

Requête IA
Bloc technique
Les blocs techniques permettent de créer des scénarios plus complexes et innovants.
Ils ont généralement aucun ou peu d'impact visuel, et se concentrent sur la logique de déroulement de votre scénario.
Ce bloc est disponible uniquement via le Menu de création de blocs rapide.
Le bloc Requête IA est un bloc technique, nécessitant de bonnes connaissances dans l'interaction avec des IA génératives de type Chat GPT.
Ce bloc permet de communiquer en temps réel avec une IA, exactement comme vous le feriez en écrivant à Chat GPT : un texte en entrée, et une réponse de l'IA en sortie. La différence avec Chat GPT est que votre prompt est écrit dans votre module VTS, et que la réponse de l'IA sera stockée dans des variables, que vous pourrez ensuite exploiter dans votre module. Votre prompt peut lui-même être composé de variables, ce qui permet de faire travailler l'IA sur des éléments spécifiques du scénario en cours d'exécution chez l'apprenant.
Interroger l'IA se fait via une requête web, ce qui nécessite une connexion internet. Si la requête réussi et que l'IA a bien pu générer une réponse, le bloc Requête IA sortira par sa première sortie, avec la coche verte. Si la requête échoue, quelle qu'en soit la raison, le bloc Requête IA sortira par sa deuxième sortie, avec la croix rouge. Ainsi, il faut toujours bien définir ce qu'il se passe si cette deuxième sortie est déclenchée, pour spécifier comment le scénario doit se comporter en cas d'erreur (problème de réseau, ou autre). Nous détaillerons plus loin les différents types d'erreur possibles et comment les gérer.
Quelques remarques techniques :
- L'exécution de ce bloc durant le scénario joué par l'apprenant nécessite une connexion internet.
- Le modèle d'intelligence artificielle utilisé par ce bloc est celui d'OpenAI. Similaire donc à Chat GPT.
- Pour fonctionner, ce bloc doit être paramétré avec une clé API d'un compte OpenAI valide. C'est-à-dire que votre organisation doit posséder un compte OpenAI.
Avant de regarder en détails les paramètres du blocs, voyons quelques exemples d'utilisation concrète.
Exemple 1 : une question simple, prévue à l'avance
Pour commencer avec un exemple basique, il est possible d'utiliser ce bloc pour envoyer un simple message à l'IA.
Par exemple lui poser une question : Quel est le plus grand mammifère marin ?
Cela se fait en écrivant tout simplement cette question dans le champ "Message" du bloc (le "prompt"), sans modifier aucun autre paramètre. Le bloc Requête IA va se charger d'envoyer ce message à l'IA, et de récupérer sa réponse dans la variable _aiResponse (variable personnalisable si besoin). Cette variable est ensuite affichable par exemple dans un bloc Message, comme ici :
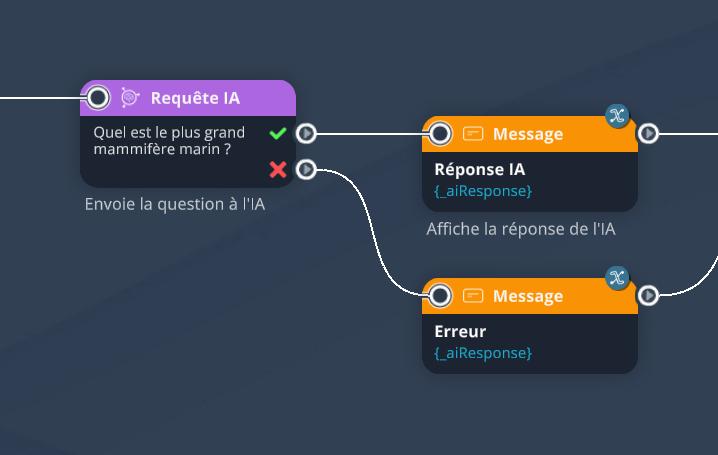
Si nous exécutons ce graphe, voici un résultat possible :

Comme il s'agit d'une réponse générée par intelligence artificielle, le résultat produit sera toujours un peu différent d'une génération à l'autre.
Exemple 2 : permettre à l'apprenant de discuter avec l'IA
En ajoutant un simple bloc Formulaire avant le bloc Requête IA, nous pouvons demander à l'apprenant de saisir lui-même les messages à envoyer à l'IA. Le bloc Formulaire permet de récupérer le message saisi dans une variable, nommée par exemple message, qui peut ensuite être insérée tel quel dans le champ "Message" du bloc Requête IA. L'apprenant aura ainsi écrit le prompt à notre place.
Il suffit ensuite d'afficher la réponse de l'IA comme dans l'Exemple 1 via un bloc Message, puis de reboucler sur le bloc Formulaire avec des blocs Relier, pour que l'apprenant puisse continuer à discuter avec l'IA.
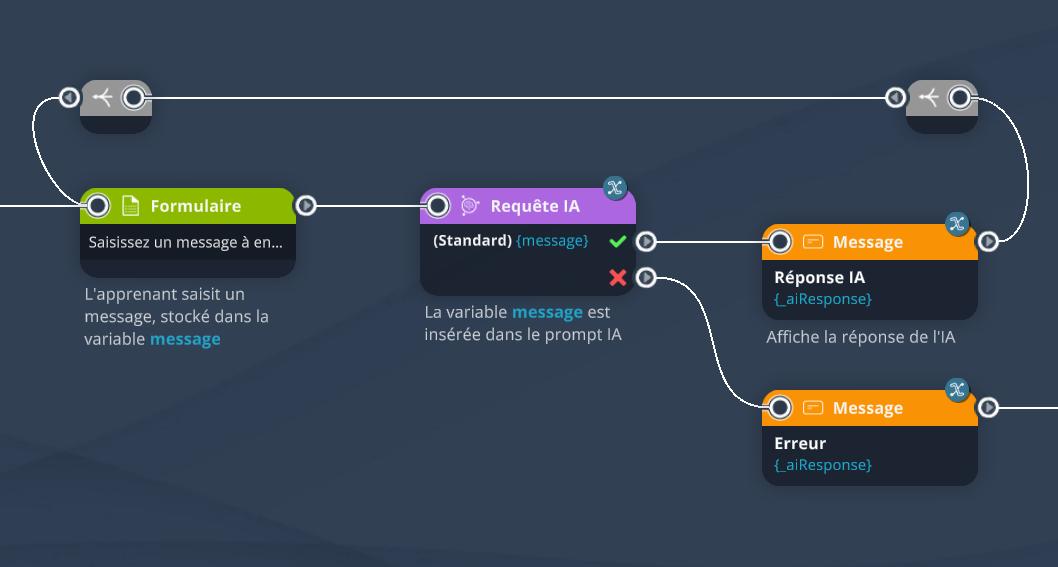
L'IA peut se souvenir des précédents messages, de manière à tenir une conversation cohérente comme avec Chat GPT.
Exemple 3 : un prompt hybride
Le prompt de l'IA n'a pas à être entièrement variable. Celui-ci peut contenir certaines parties pré-écrites par le concepteur, et d'autres qui sont variables, en fonction des choix de l'apprenant.
Par exemple, ici, nous demandons à l'apprenant via à bloc Formulaire de saisir le nom d'un personnage historique dont il veut découvrir l'histoire. Ce nom est stocké dans une variable nom, qui est ensuite insérée dans le prompt de l'IA de la manière suivante : Raconte moi la vie de {nom} en quelques paragraphes. La réponse de l'IA est ensuite affichée dans un bloc Message.
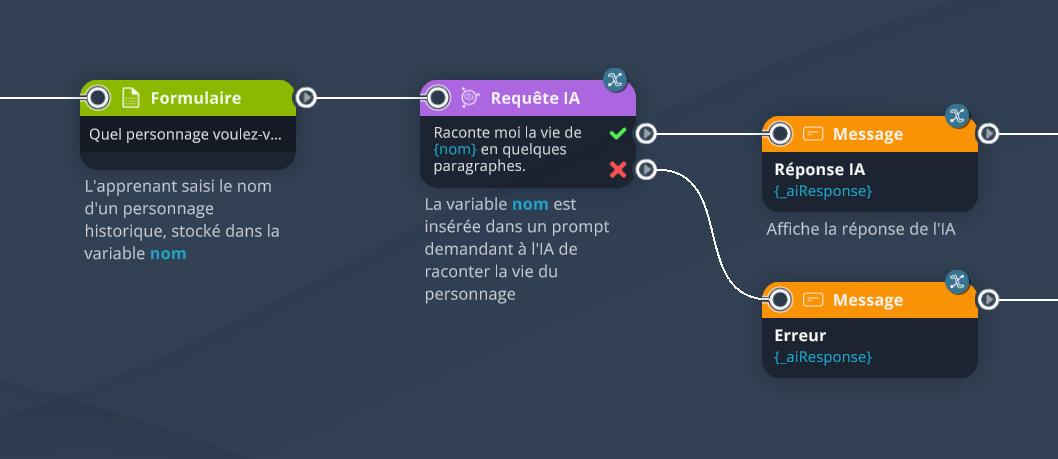
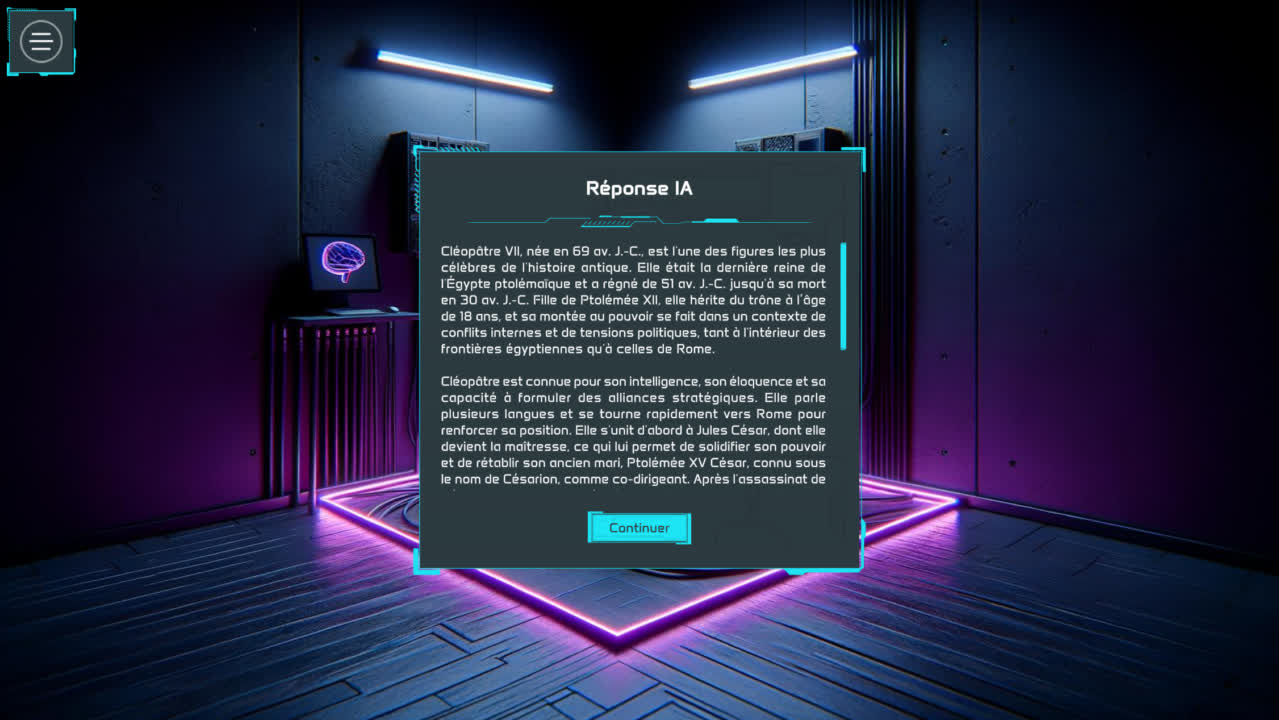
Voici un résultat possible si l'apprenant saisi le nom "Cléopâtre" :
Configuration
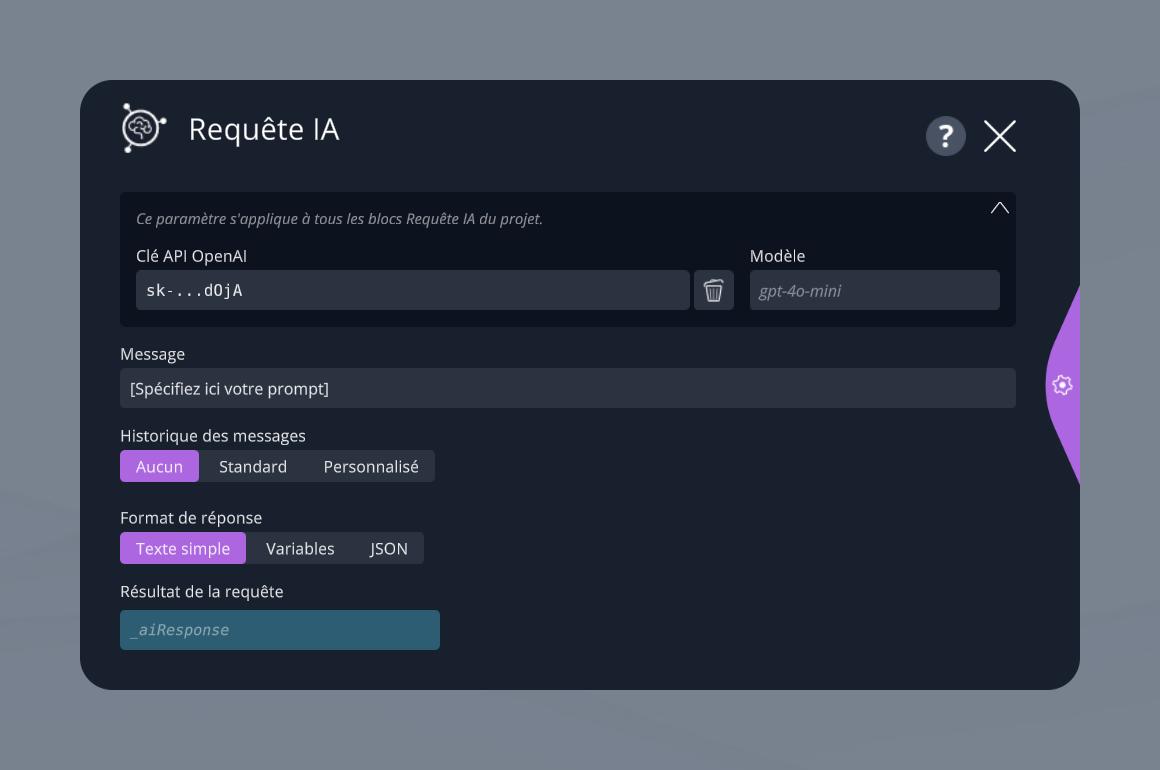
Clé OpenAI
Indiquez ici la clé API d'un compte OpenAI valide pour que le bloc puisse se connecter à l'IA. Si vous ne savez pas comment obtenir une telle clé, adressez-vous à votre DSI pour en savoir plus. Cette clé est commune à tous les blocs Requête IA du projet en cours. Vous n'aurez pas besoin de la spécifier à chaque fois.
Une remarque sur la sécurité : cette clé permet à n'importe qui de faire appel à votre compte OpenAI pour générer des textes, des images, ou autres. Chaque opération coûte de l'argent. Ainsi, il est important de ne pas partager cette clé à n'importe qui. C'est pourquoi, par mesure de sécurité, une fois saisie dans ce champ, cette clé n'est plus lisible car majoritairement masquée, au cas où vous partageriez votre projet à quelqu'un qui pourrait récupérer votre clé OpenAI. La clé reste néanmoins stockée dans le projet VTS lui-même, et si la personne duplique votre projet et le modifie, elle pourra utiliser des blocs Requête IA faisant appel à votre compte OpenAI. Avant de partager votre projet, pensez donc à supprimer votre clé OpenAI du projet.
Modèle
Optionnellement, indiquez ici un modèle spécifique à utiliser par l'IA. Par défaut, le modèle gpt-4o-mini est utilisé. Il s'agit d'un modèle rapide, puissant et peu onéreux, qui est donc très adapté pour un usage dans un module VTS. Pour plus d'information sur les modèles d'IA disponibles, vous pouvez consulter la documentation d'OpenAI dédiée : Models.
Message
Il s'agit du paramètre central de ce bloc, le seul qu'il est indispensable de spécifier dans 100% des cas : le prompt. Écrivez ici comme vous le feriez lorsque vous vous adressez à Chat GPT. Vous pouvez insérer des variables dans ce prompt, permettant de le personnaliser en fonction du déroulement du scénario.
Historique des messages
Cette option concerne la manière dont l'IA doit se souvenir des messages précédemment échangés avec elle au cours du même scénario. Trois modes d'usage de l'historique sont disponibles :
- Aucun : l'IA n'a pas de mémoire. Dans ce mode, chaque nouveau bloc Requête IA donc est comme le début d'une nouvelle conversation.
- Standard : l'IA se souvient de tous les messages échangés précédemment via d'autres blocs Requête IA eux aussi configurés en mode Standard.
- Personnalisé : dans ce mode, vous pouvez saisir un identifiant unique personnalisé (dans le paramètre Identifiant d'historique), par exemple Discussion 3. L'IA se souviendra alors de tous les messages échangés précédemment via d'autres blocs Requête IA eux aussi configurés en mode Personnalisé et utilisant le même identifiant unique.
Si vous utilisez un historique (Standard ou Personnalisé), un nouveau paramètre Max. messages est aussi disponible, vous permettant de définir le nombre maximum de messages à prendre en compte par l'IA. L'intérêt de ce paramètre est d'éviter d'avoir des conversations dont l'historique grandit à l'infini, car cela pourrait générer de très longs contextes pour l'IA, ce qui augmente la durée des requêtes, et augment le coût de la génération de chaque réponse.
Format de réponse
L'IA peut répondre de 3 manières différentes :
- Mode "Texte simple" : l'IA répond sous la forme d'un simple texte. C'est le mode par défaut.
- Mode "Variables" : ce mode permet d'indiquer à l'IA de répondre sous la forme de variables plutôt qu'un texte, rendant ainsi la réponse beaucoup plus simple à exploiter dans la suite d'un scénario. Consultez la sous-section dédiée pour les informations détaillées concernant l'utilisation de ce mode.
- Mode "JSON" : il s'agit d'un mode de réponse avancé, permettant d'aller plus loin que le mode "Variables". Indiquez à l'IA un format de données JSON qu'elle devra suivre pour vous répondre. La variable de retour sera donc remplie d'une chaîne de caractères représentant une structure de données JSON respectant le format spécifié. Cette réponse pourra être désérialisée via la fonction fromJson.
Résultat de la requête
Par défaut, la réponse de l'IA est enregistrée dans la variable _aiResponse. Vous pouvez spécifier dans ce champ une variable personnalisée si vous le souhaitez.
Paramètres avancés
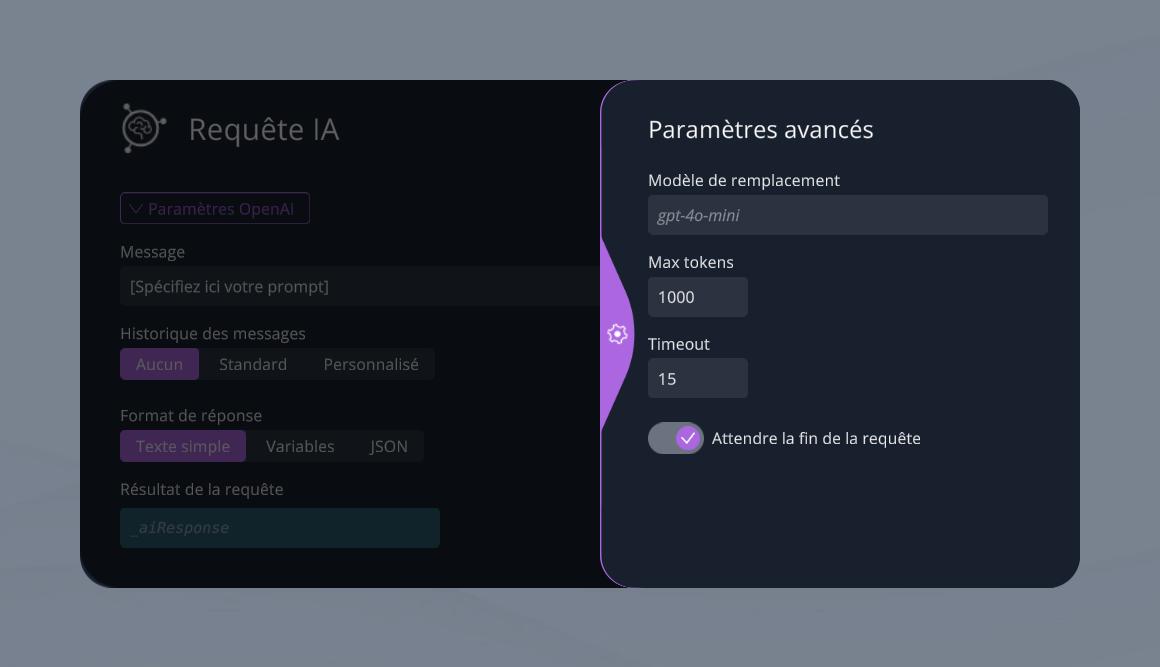
Modèle de remplacement
Vous pouvez optionnellement indiquer un modèle d'IA à utiliser spécifiquement pour ce bloc, en ignorant donc le modèle défini de manière globale pour le projet.
Max tokens
Définissez un nombre maximum de tokens à consommer lors de la requête. Vous trouverez pour plus d'informations sur le fonctionnement des tokens OpenAI dans cet article dédié.
Timeout
Durée maximum de la requête. Si la requête n'est pas terminée après cette durée, la sortie erreur du bloc est déclenchée (la 2e sortie), et la sortie de succès ne sera pas déclenchée.
Attendre la fin de la requête
on Le bloc attend que la requête web retourne une réponse avant de passer à la suite du graphe. off Le bloc sort immédiatement vers la suite du graphe dès que la requête a été lancée, sans attendre de réponse.
Gestion des erreurs
Lorsqu'une erreur survient lors de la requête à l'IA, la deuxième sortie du bloc est déclenchée. Vous pouvez ainsi décider de comment votre scénario doit se comporter en cas d'erreur : retenter une requête immédiatement, proposer à l'apprenant un chemin alternatif qui ne nécessite pas l'IA, etc.
Dans tous les cas, le détail de l'erreur est alors assigné à la variable de réponse _aiResponse (ou la variable personnalisée que vous avez spécifié). Vous pouvez ainsi éventuellement traiter le contenu de l'erreur pour faire réagir votre scénario de manière spécifique.
- ${ child.title }